The internet is made up of text. Lots and lots of text.
Whether it’s a website, URL, product description or blog post the web text we see on our screens may seem simple, but behind the scenes, there’s a lot going on. The thousands of languages spoken around the world today is a lot to organize and process let alone punctuation, symbols, and the ever-growing list of emojis we use on a daily basis.
This is where Unicode comes in, providing an orderly system for all text on the web, but also potential risks when exploited. These risks can be mitigated by web filters that are able to process Unicode characters and not just the ASCII subset that represents 128 characters in English language only.
What is Unicode?
Unicode is described as “the standard for digital representation of the characters used in writing all of the world’s languages”. Used by all modern computers, it acts as the foundation for processing text on the internet and is the uniform means for storing, searching, and interchanging text in any language.
Unicode is a type of character encoding. It assigns each character of a different language a unique numeric value that is applicable no matter the platform, facilitating communication between computers and devices worldwide, without any translation.
How Does Unicode Work?
The Unicode standard expresses over 140,000 characters from the world’s alphabet as well as symbols, ideograph sets, historical texts and emojis. Characters are each assigned a unique code, called a “code point”. The code point starts with “U” for “Unicode” trailed by a distinct string of characters. For example, the letter “A” is represented by “U+0041” in code point.
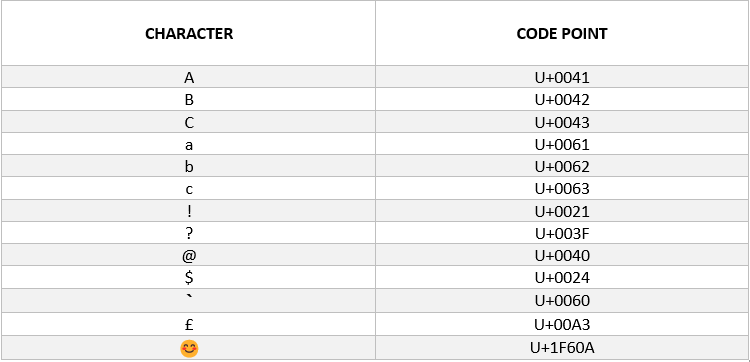
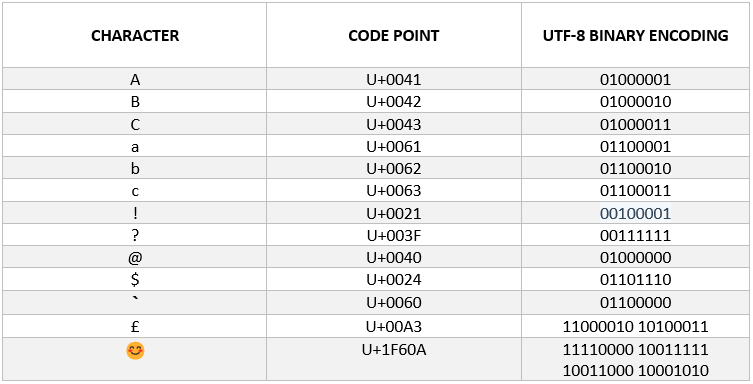
This standardized way of expressing characters isn’t enough, it is only a piece of the puzzle. Computers store data, like text characters as binary. Different encoding forms like UTF-8, UTF-16 and UTF-32 is then used to translate the code point into a string of binary. This allows computers to understand and store the text files. UTF-8 is the most common character encoding method. Today, over 90% of websites on the internet store text this way due to its proficiency for storing text containing any character.
Why is it Important to Filter Unicode?
Unicode provides universal character encoding for any language in all modern software and information technology protocols. With so many languages bring many similarities between characters, for example, “O” and “Ò” or “c” and “ç”. These similarities can be exploited as a way around content filters that do not have the ability to process Unicode.
Utilizing Unicode characters, students for example, can access potentially harmful or blocked sites by replacing letters with similar looking characters. If the filter does no process Unicode, then it will not be able to determine the altered words in the search bar.
In addition to filter bypassing, more languages are in use on the internet today than ever before that are non-Latin based, like English. Users around the world should be able to have a filter that supports their own unique language characters like Korean, Arabic or Cyrillic.
Netsweeper and Unicode
Regardless of language, symbol, or emoji being used, your web filter needs to be designed to handle every option. To provide the best content filtering for its users, the ability to filter Unicode and not just ASCII is a must. Netsweeper is able to filter in 47 languages as well as Unicode, with consistent updates to categories and languages that are then shared by all Netsweeper deployments globally.
For additional content on languages filtering check out these blog post blogs below